ML Lecture 6: Brief Introduction of Deep Learning
Ups and downs of Deep Learning 1958 perceptron (linear model) 1968 perceptron has limitation 卡車與坦克車分辨其實是因為照片本身亮度就有差所以分辨得出來 1980s multi-layer perceptron
- Do not hace signigicant difference from DNN today
1986 Backpropagation
- Usually more than 3 hidden layers is not helpful
1989 1 hidden layer is ‘good enough’, why deep? 2006 RBM initialization (breakthrough) 有用RBM找初始值叫deep learning; 反之,叫multi-layer perceptron。但這招太複雜,卻沒有太大用處,因此現在大家都不用這招XD 2009 GPU 2011 Start to be popular in speech recognition 2012 win ILSVRC image competition
step 1. define a set of function
step 2. goodness of function
step 3. pick the best function
Step 1.
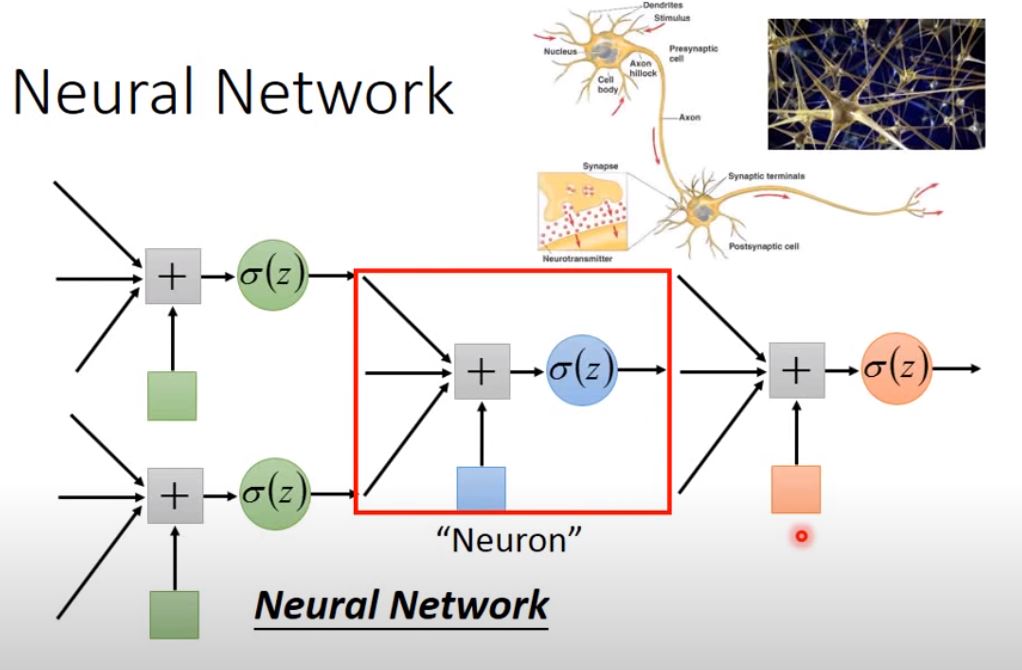
Note: Fully Connect Feedforward Network 每層的每個neuron都會和前一層所有neuron output連接
Input a vector, output vector: \(\textbf{y} = f(\textbf{x})\) Architecture: input layer > hidden layer > output layer
Deep = Many hidden layers
How a network work ? Matrix Operation.
What hidden layer do ? Feature engineering.
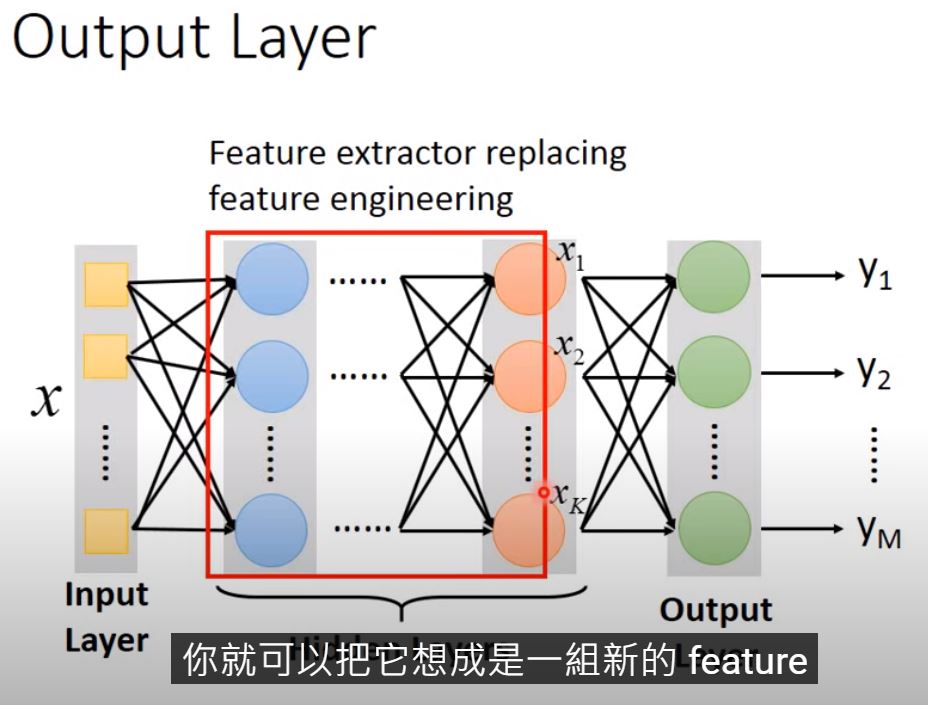
Output layer = Multi-class classifier Usually, add a softmax function to output layer where the output value represent a probability distribution.
For example,
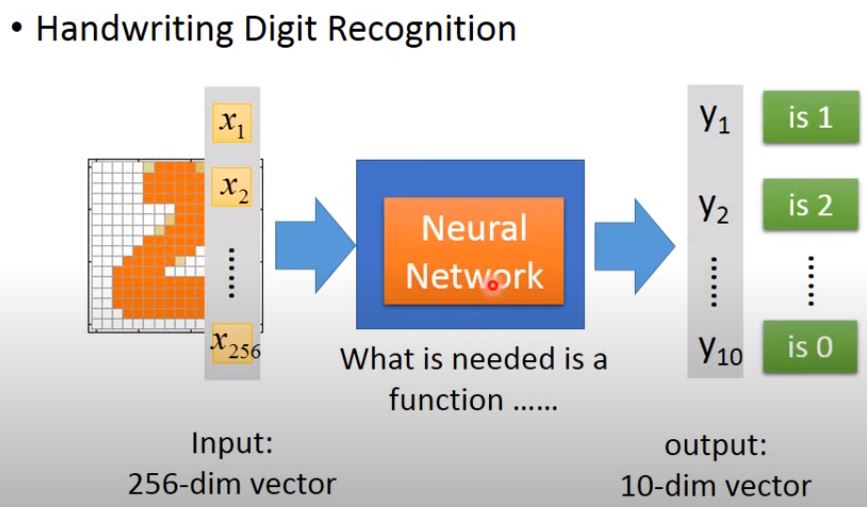
Question:
- how many layers? How many neurons for each layer? trial and error + intuition 傳統機器學習很吃好的feature 但在影像與語音上,人類很難自己找出有用的feature
- Can the structure be automatically determined? e.g. Evolutionary Artificial Neural Networks 基因演算法(余天立老師)
- Can we design the network structure, not Fully Connected? e.g. Convolutional Neural Network (CNN)
Step 2 & 3
Define a Loss function for the problem,
such Cross Entropy, MSE, MAPE …
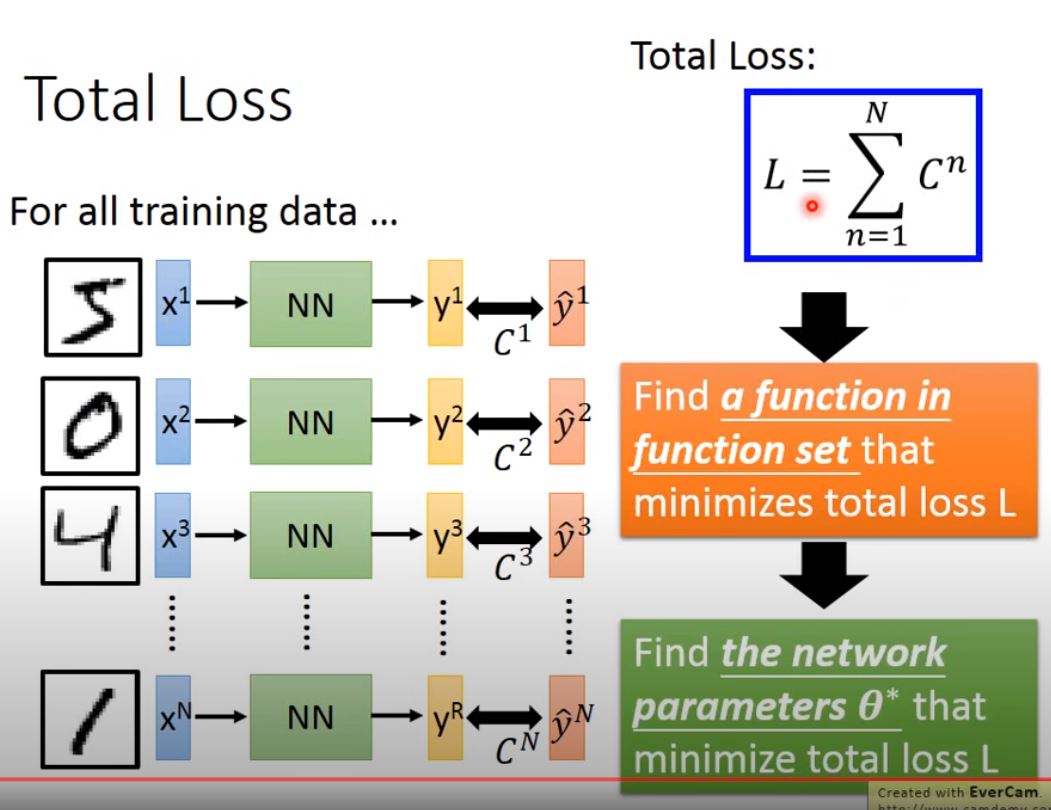
Use Gradient Descent to find the parameter to minimize the loss.

Note: the updating of weight \(\partial L / \partial w\) can be computed by Backpropagation.

Universality Theorem: Any continuous function f \(f: R^N \rightarrow R^M\) can be realized by a network with one hidden layer given enough hidden neurons.
So, why “Deep” neural network not “Fat” neural network? next lecture.
Fat and Short v.s. Thin and Tall
公平地參數數量應該要一樣
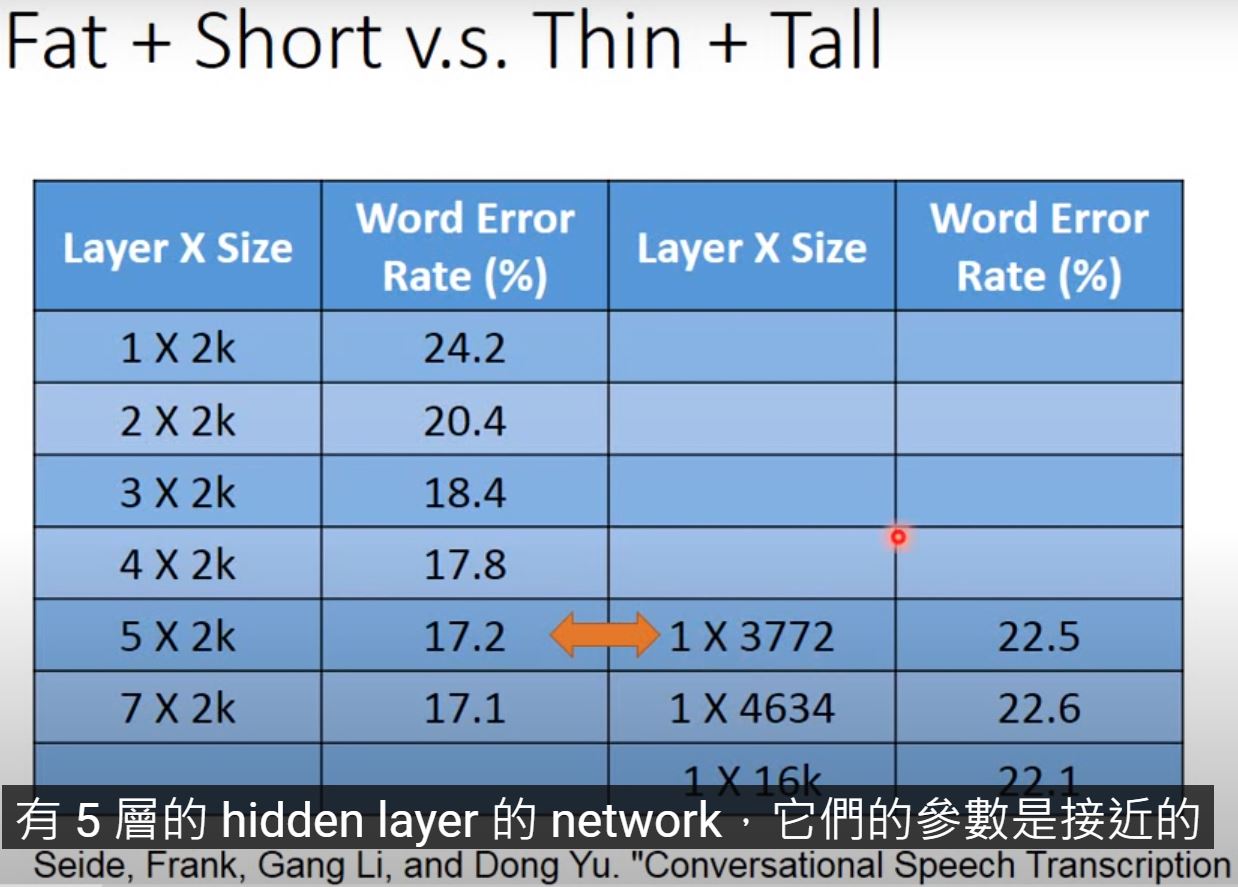
如果我們只是單純增加參數而建多層(fat and short),對performance的提升是比較少的。
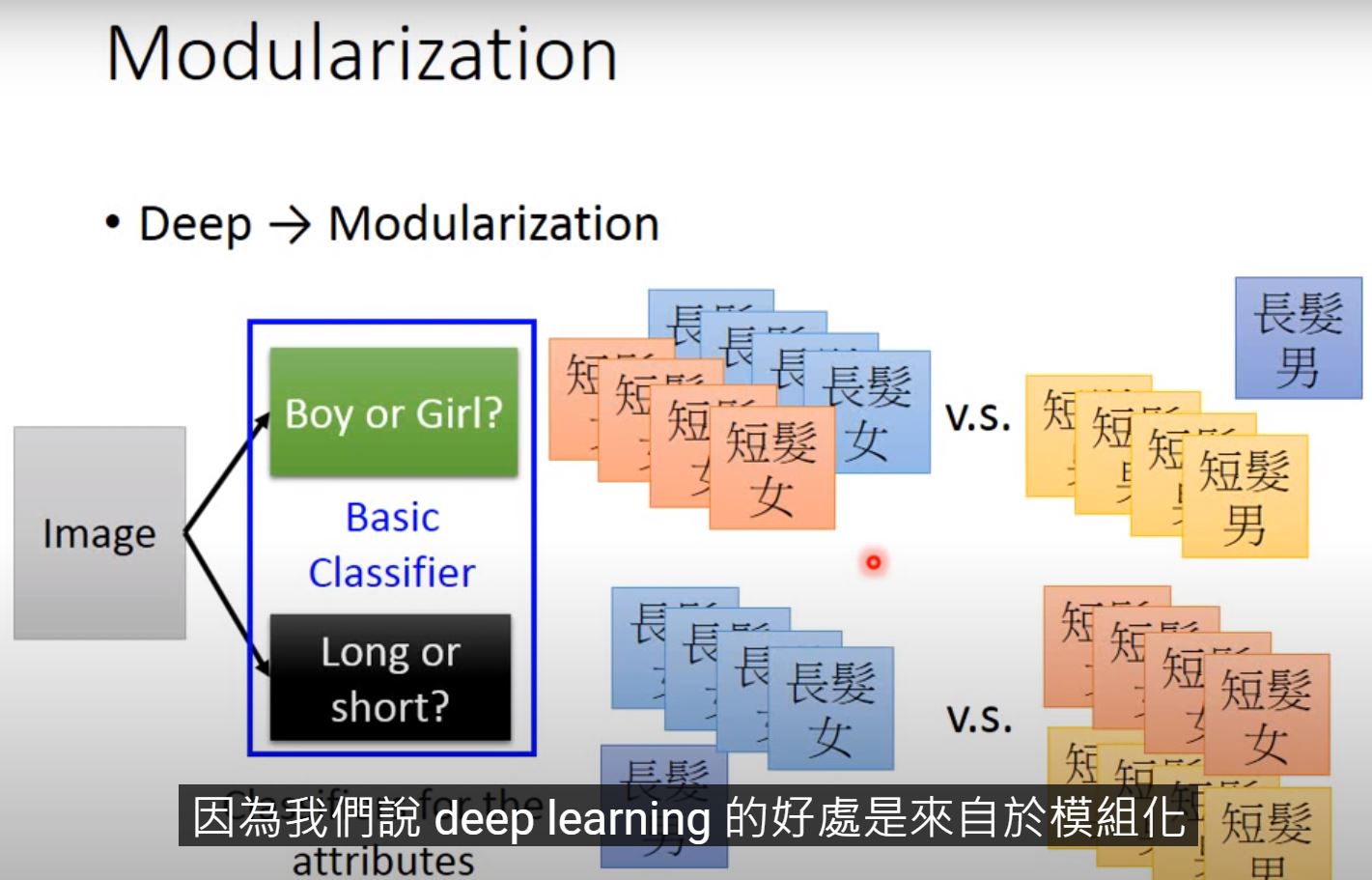
為什麼? ‘deep’ 隱含 modularization (模組化,切分成小問題讓classifier去學)
譬如,任務是分類長短髮的男女生
basic classifier: 分男女、分長短髮
影像和語音領域上 Speech: the hierarchical structure of human languages
分析 “what do you think”
- Phoneme
- Tri-phone
- state
The first stage of speech recognition
- Classification: Input = acoustic feature (聲音訊號取windowa描述特性), Output = state. 決定一個acoustic feature屬於哪一個state.
傳統上,Gaussian Mixture Model (GMM)說each state has a stationary distribution for acoustic features.
→ 延伸 subspace GMM