ML Lecture 10: Convolutional Neural Network
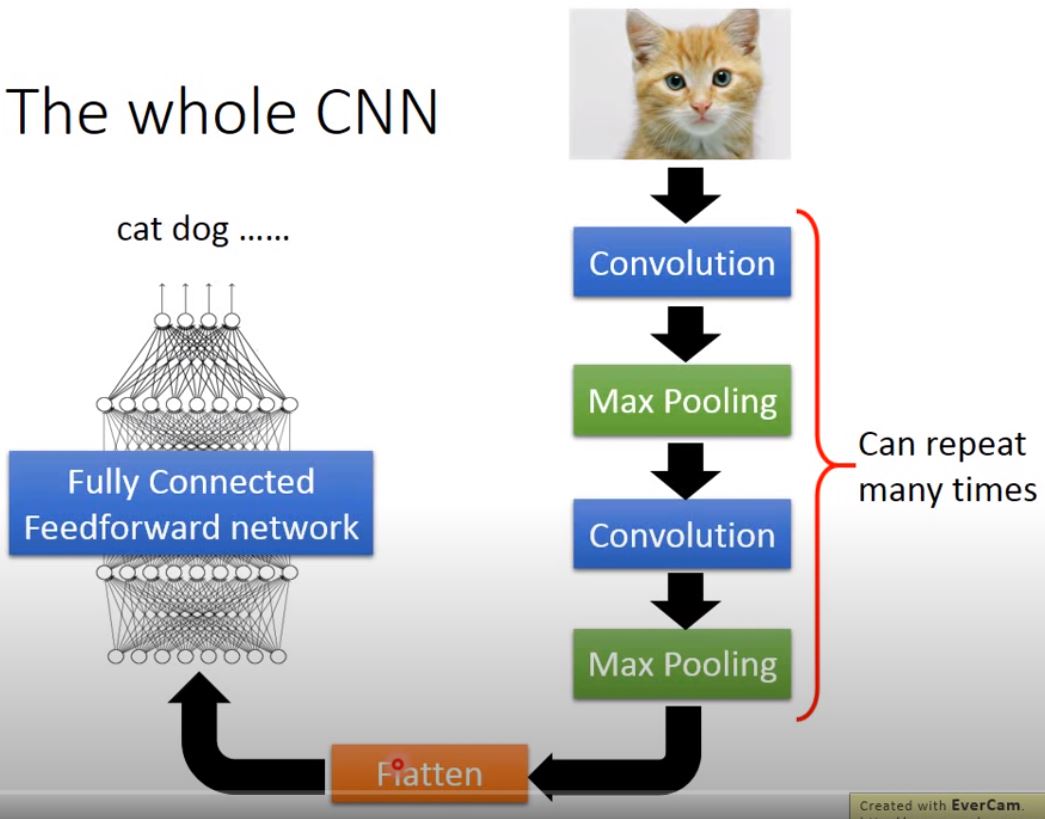
Convolutional Neural Network
Concept of neural network: each neuron = each basic classifier
Problem: the number of parameter too large !

Property of convolution method: 1. A neuron does not have to see the whole image to discover the pattern. 2. The same pattern appear in different regions. 3. Subsample the pixels will not change the object recognition.
NOTE: 1 and 2 use Convolution; 3 using Max Pooling.
flow of procedure: image > convolution > max pooling > convolution > max pooling … > flatten > fully connected feedforward network
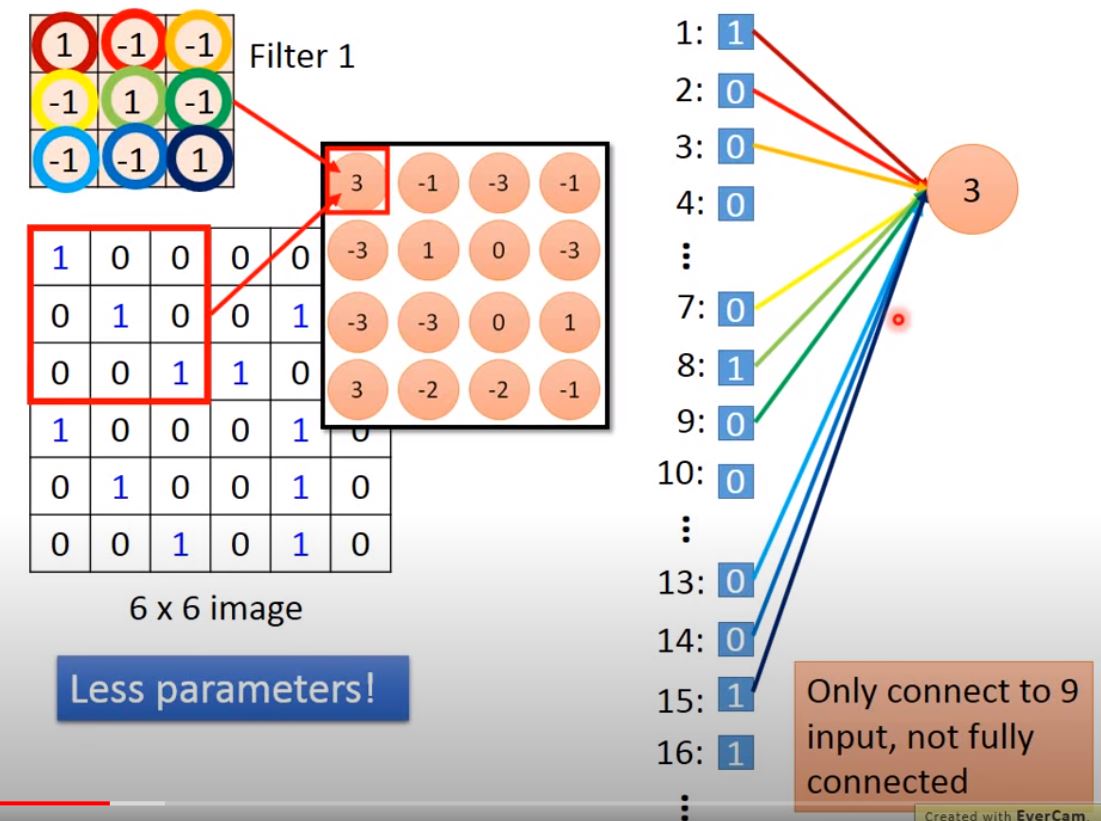
- Filter: filte the pattern with equal value meaning the same pattern
- Stride: the moving step of a filter.
- kernal size: the size of a filter.

Each Filter will get a Feature Map. e.g. 6x6 image with 3x3 filters, get 4x4 matrix feature map for each filter.
Convolution = Partially connected For each Filters: - filter 1 take only 9 (3x3) input, and the output is like a neuron. - when moving (stride=1), a new neuron is generated by filter 1. note that the same filter share the same parameter.
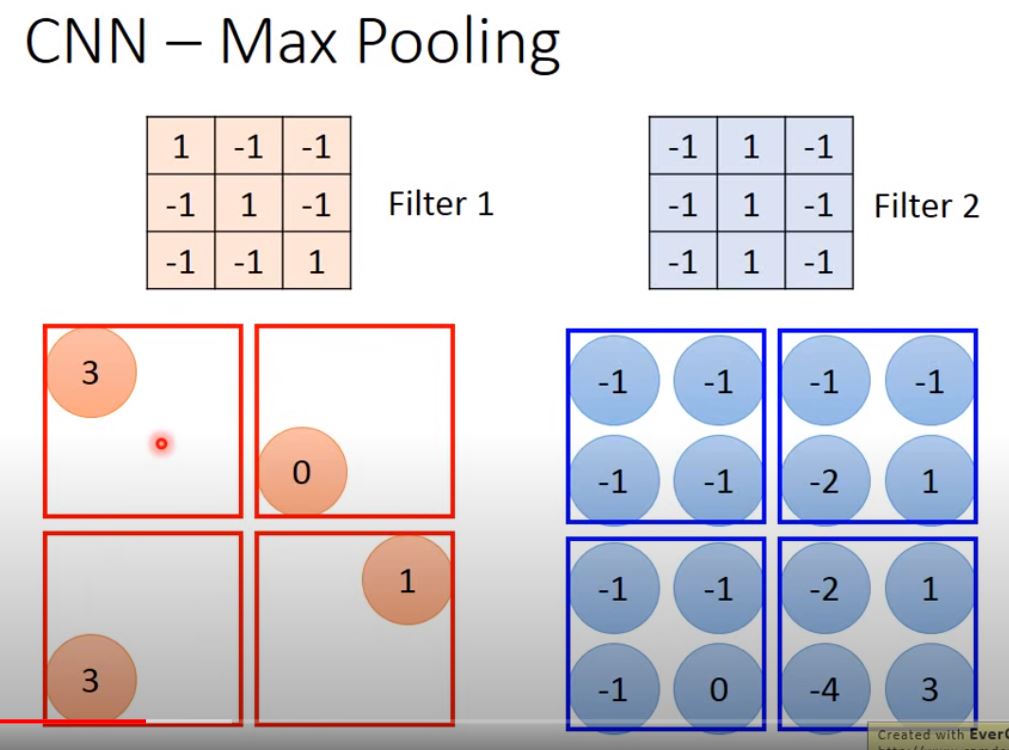
After all filter is done, Max Pooling: take max or mean of matrix in a window.
Note:
- the number of filter should be the number of feature map. Each filter consider all channels. Take more look at Colorful image. 黑白的image,input的是一個matrix,如果是彩色的image呢?彩色的image就是由RGB組成,是好幾個matrix疊在一起的立方體,如果我今天要處理彩色的image,要怎麼做呢? 這時filter就不再是一個matrix,它是一個立方體,彩色的image input是3 * 6 * 6,filter就是3 * 3 * 3,你的filter的高就是3,做convolution的時候,把filter的9個值跟image裡的9個值做內積,可以想像成filter的每一層都分別跟image的三層做內積,得到是一個三層的output,每一個filter同時就考慮了不同顏色所代表的channel.
The “2D” is the space in which the filter is allowed to move (2 direction only).
What does CNN learn?
For filter
In the same convolution layer,
Suppose the output of the k-th filter is a 11x11 matrix, \(a_{ij}^k\),
then define degree of the activation of the k-th filter: \(a^k = \sum_{i=1}^{11}\sum_{j=1}^{11} a^k_{ij}\),
we can find the image that maximize degree of activation as
\(x_k^* = \mathop{\arg\max}_x a^k , \hspace{0.1cm} for \, k=1,2,...\)
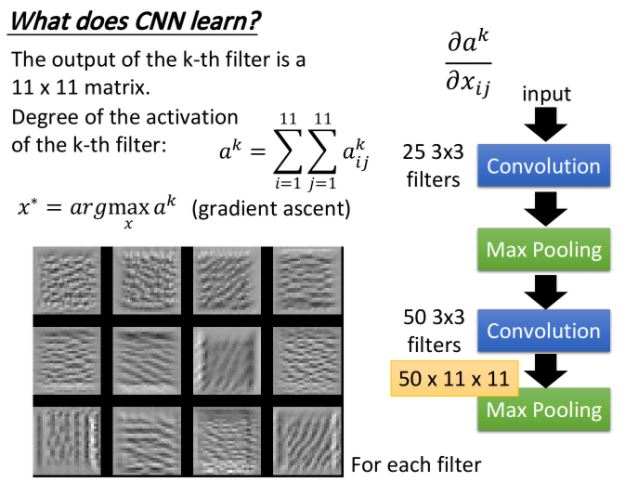 上圖僅挑選了12張image作為展示(50個filter理論上可分別找50張image使對應的activation最大),這些image有個共同特徵,它們反覆出現的某種texture(紋路),比如說第三張image上佈滿了小小的斜條紋,這意味著第三個filter的工作就是detect圖上有沒有斜條紋,要知道現在每個filter檢測的都只是圖上一個小小的範圍而已,所以圖中一旦出現一個小小的斜條紋,這個filter就會被activate,相應的output也會比較大,所以如果整張image上佈滿這種斜條紋的話,這個時候它會最興奮,filter的activation程度是最大的,相應的output值也會達到最大。
上圖僅挑選了12張image作為展示(50個filter理論上可分別找50張image使對應的activation最大),這些image有個共同特徵,它們反覆出現的某種texture(紋路),比如說第三張image上佈滿了小小的斜條紋,這意味著第三個filter的工作就是detect圖上有沒有斜條紋,要知道現在每個filter檢測的都只是圖上一個小小的範圍而已,所以圖中一旦出現一個小小的斜條紋,這個filter就會被activate,相應的output也會比較大,所以如果整張image上佈滿這種斜條紋的話,這個時候它會最興奮,filter的activation程度是最大的,相應的output值也會達到最大。
For neuron
 找到的結果如上圖所示,同理這裡僅取出其中的9張image作為展示,你會發現這9張圖跟之前filter所觀察到的情形是很不一樣的,剛才我們觀察到的是類似紋路的東西,那是因為每個filter考慮的只是圖上一部分的vision,所以它detect的是一種texture;但是在做完Flatten以後,每一個neuron不再是只看整張圖的一小部分,它現在的工作是看整張圖,所以對每一個neuron來說,讓它最興奮的、activation最大的image,不再是texture,而是一個完整的圖形。
找到的結果如上圖所示,同理這裡僅取出其中的9張image作為展示,你會發現這9張圖跟之前filter所觀察到的情形是很不一樣的,剛才我們觀察到的是類似紋路的東西,那是因為每個filter考慮的只是圖上一部分的vision,所以它detect的是一種texture;但是在做完Flatten以後,每一個neuron不再是只看整張圖的一小部分,它現在的工作是看整張圖,所以對每一個neuron來說,讓它最興奮的、activation最大的image,不再是texture,而是一個完整的圖形。
For output
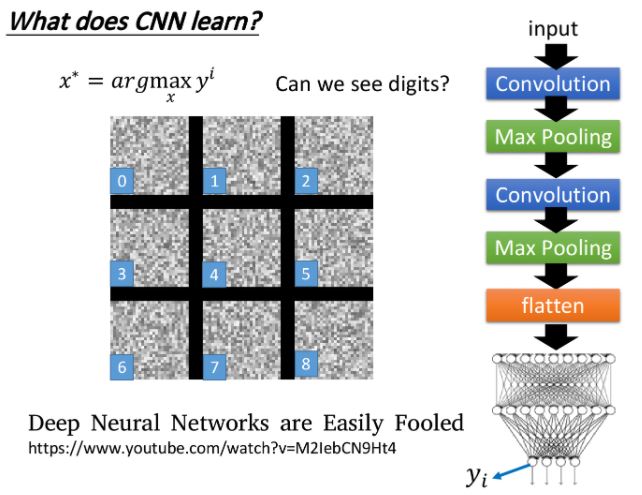
上面每一張圖分別對應著真實數字0-8,發現數字1所對應neuron output值最大的image其實一點也不像1,就像是電視機壞掉的樣子。為了驗證程序有沒有bug,這裡做一個實驗,把上述得到的image作為testing data丟到CNN裡面,結果classify的結果確實認為這些image就對應著數字0-8。
所以neural network所學到的東西跟我們人類想像認知是不一樣的 !
-
Penalizing on all pixel values \(x_{ij}\), we want a image \(x_{ij}\) contains less noise (some of them be 0):
\[x^* = \mathop{\arg\max}_x (y^i - \sum_{i,j} |x_{ij}|)\]我們對x做一些regularization,對找出來的x做一些constraint(限制約束),我們應該告訴machine說,雖然有一些x可以讓你的y很大,但是它們不是數字。 這次我們希望找一個input x,它可以同時使\(y^i\)最大且讓\(\sum_{i,j}x_{ij}\)越小越好,亦即找出來的image,大部分的地方是沒有塗顏色的,只有少數數字筆劃在的地方才有顏色出現。
 加上這個constraint後,得到的結果會像圖右側所示一樣,已經隱約有些可以看出來是數字的形狀了。
加上這個constraint後,得到的結果會像圖右側所示一樣,已經隱約有些可以看出來是數字的形狀了。 -
Deep Dream 找一張image丟到CNN裡面去,然後把某一個convolution layer裡面的filter或是fully connected layer裡的某一個hidden layer的output拿出來,它其實是一個vector;接下來把本來是positive的值調大,negative的值調小,也就是正的更正,負的更負,然後把它作為新的image的目標
 然後用gradient descent的方法找一張image x,讓它通過這個hidden layer後的output就是你調整後的target,這麼做的目的就是,讓CNN誇大化它看到的東西——make CNN exaggerates what is sees.
然後用gradient descent的方法找一張image x,讓它通過這個hidden layer後的output就是你調整後的target,這麼做的目的就是,讓CNN誇大化它看到的東西——make CNN exaggerates what is sees.也就是說,如果某個filter有被activate,那你讓它被activate的更劇烈,CNN可能本來看到了某一樣東西,那現在你就讓它看起來更像原來看到的東西,這就是所謂的誇大化
如果你把上面這張image拿去做Deep Dream的話,你看到的結果就會像下面這個樣子
 就好像背後有很多念獸,要凝才看得到,比如像上圖右側那一隻熊,它原來是一個石頭,對機器來說,它看這張圖的時候,本來就覺得這個石頭有點像熊,所以你就更強化這件事,讓它看起來真的就變成了一隻熊,這個就是Deep Dream。
就好像背後有很多念獸,要凝才看得到,比如像上圖右側那一隻熊,它原來是一個石頭,對機器來說,它看這張圖的時候,本來就覺得這個石頭有點像熊,所以你就更強化這件事,讓它看起來真的就變成了一隻熊,這個就是Deep Dream。 -
Deep Style Deep Dream還有一個進階的版本,就叫做Deep Style,如果今天你input一張image,Deep Style做的事情就是讓machine去修改這張圖,讓它有另外一張圖的風格,如下所示
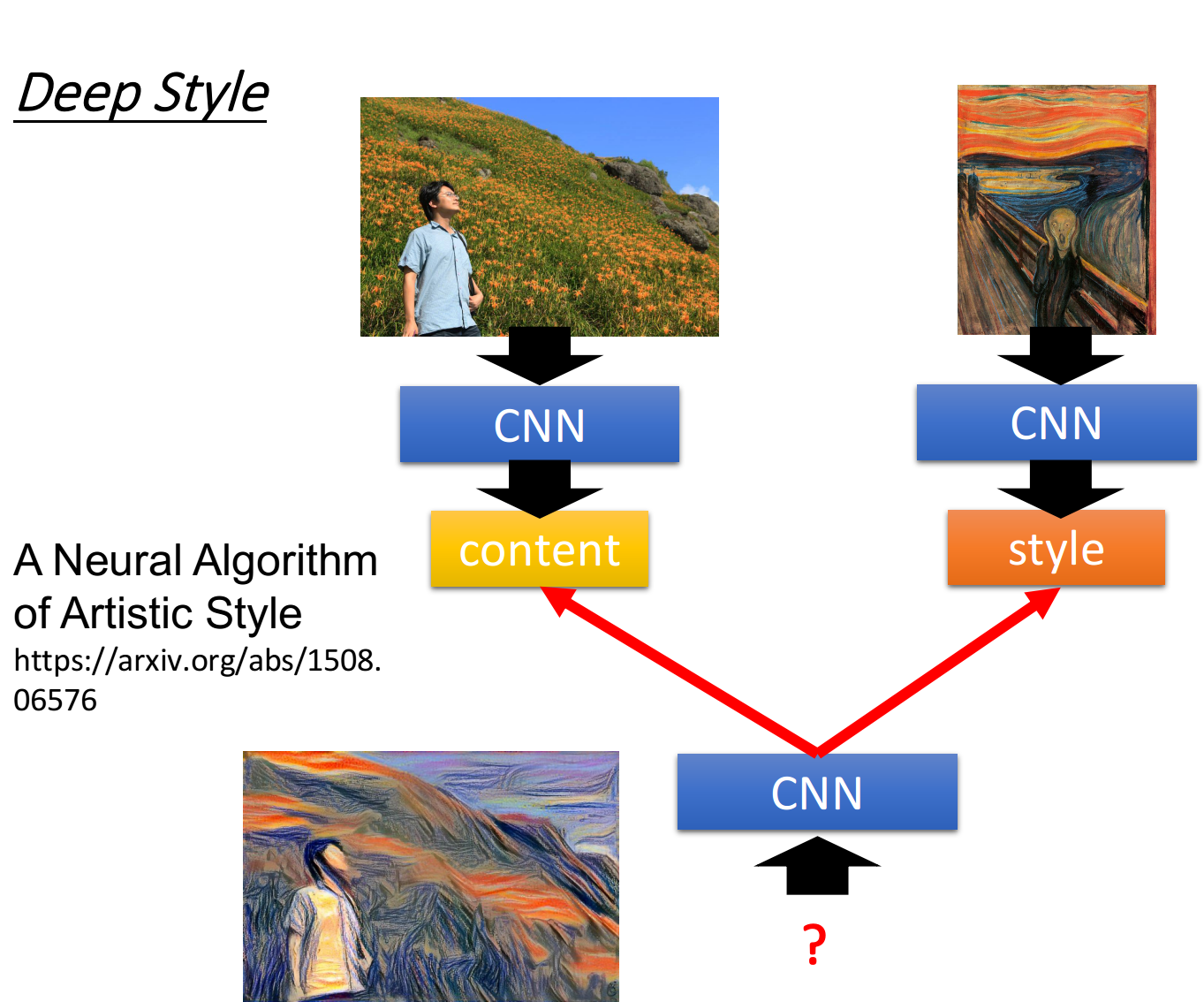
實際上機器做出來的效果驚人的好,具體的做法參考reference:A Neural Algorithm of Artistic Style
這裡僅講述Deep Style的大致思路,你把原來的image丟給CNN,得到CNN filter的output,代表這樣image裡面有什麼樣的content,然後你把吶喊這張圖也丟到CNN裡面得到filter的output ,注意,我們並不在於一個filter output的value到底是什麼,一個單獨的數字並不能代表任何的問題,我們真正在意的是,filter和filter的output之間的correlation,這個correlation代表了一張image的style
接下來你就再用一個CNN去找一張image,這張image的content像左邊的圖片,比如這張image的filter output的value像左邊的圖片;同時讓這張image的style像右邊的圖片,所謂的style像右邊的圖片是說,這張image output的filter之間的correlation像右邊這張圖片
最終你用gradient descent找到一張image,同時可以maximize左邊的content和右邊的style,它的樣子就像上圖左下角所示。
- 為什麼圍棋也適合用CNN呢?
- Alpha Go use 5x5 filter for first layer (Property 1 & 2)
- But how to explain Max Pooling ? (Property 3)
Alpha Go does not use it !

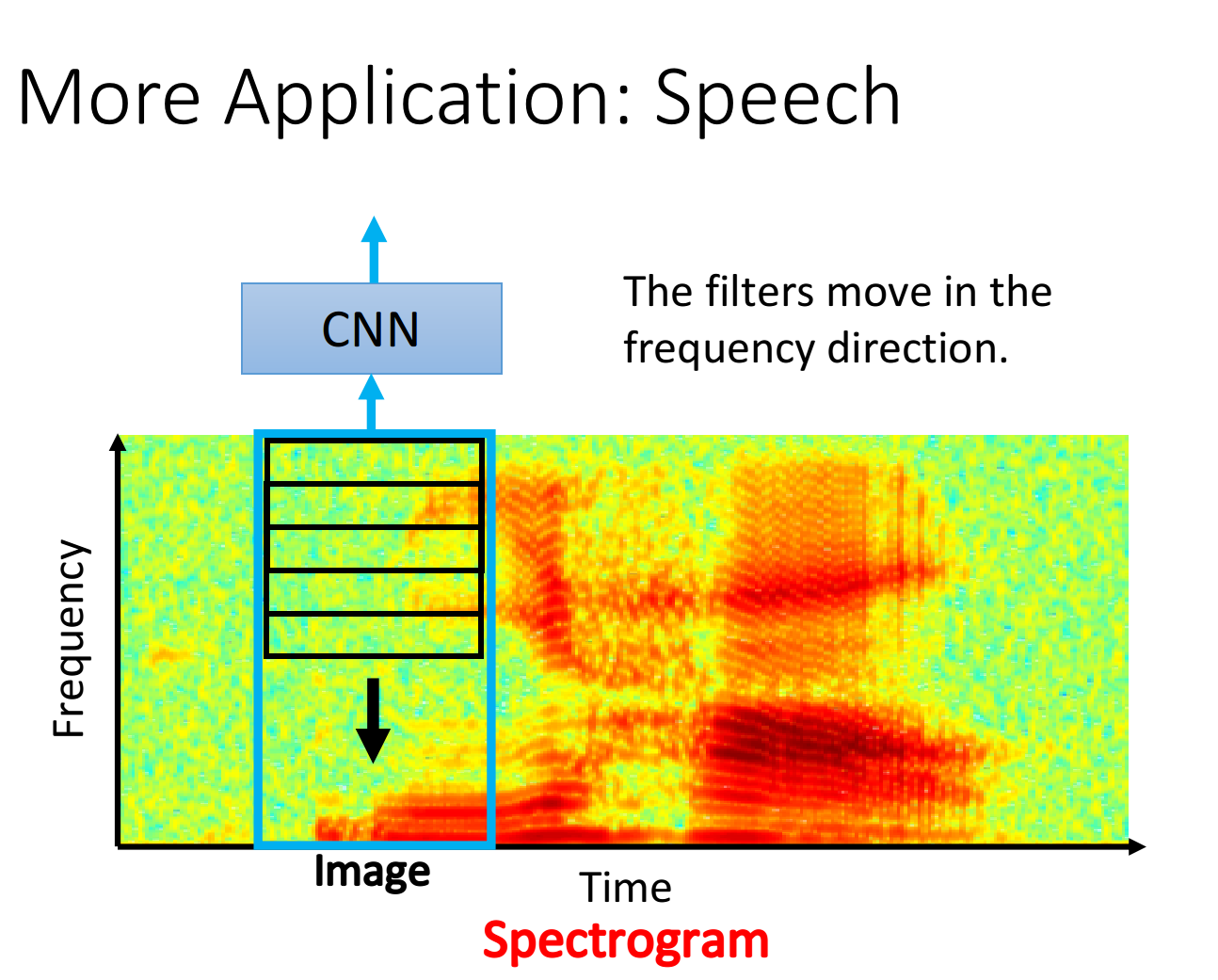
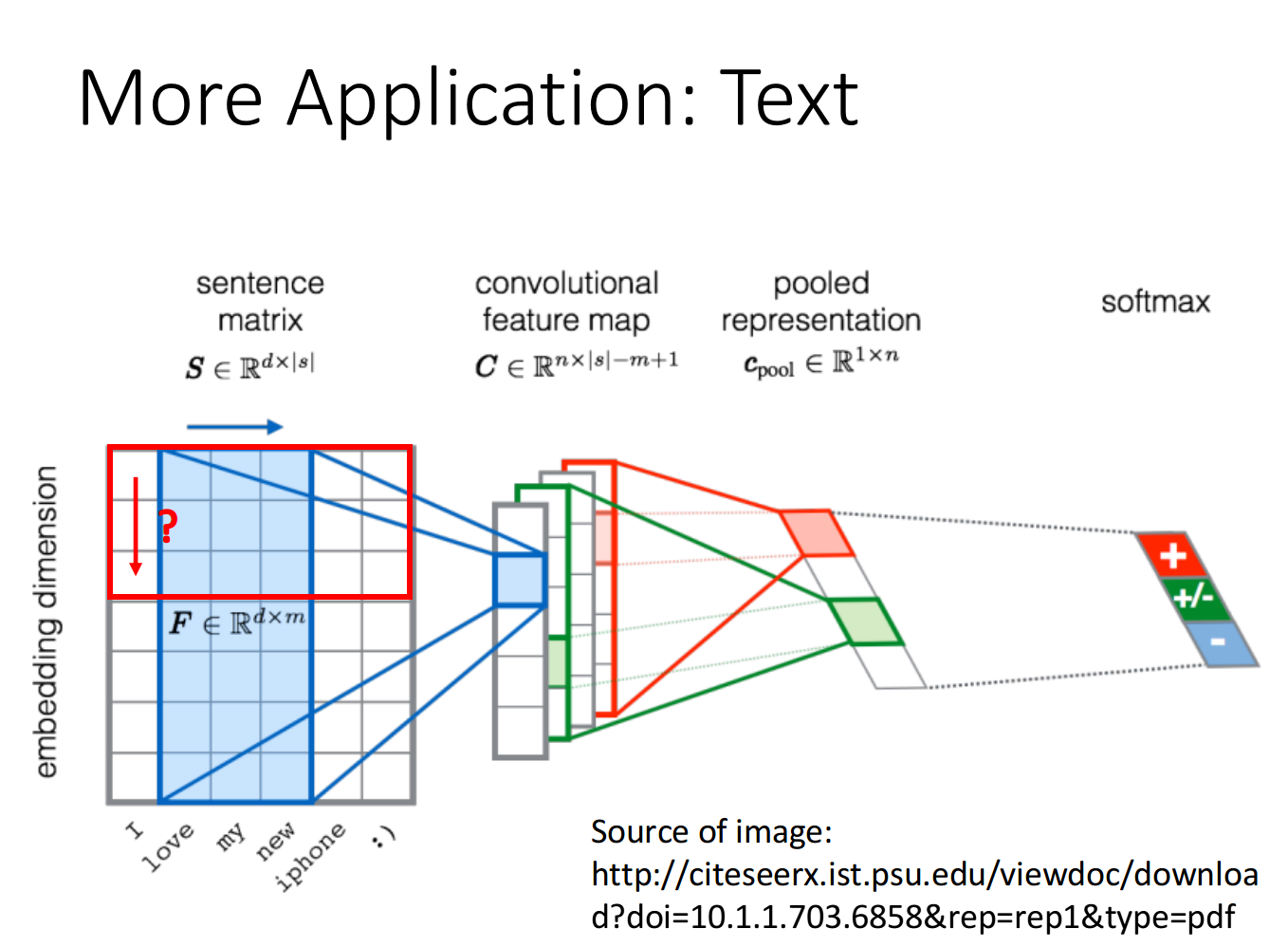
- More Application——Speech、Text
conclusion
本文的重點在於What is CNN?What does CNN do?Why CNN?
三個property
- Some patterns are much smaller than the whole image ——property 1
- The same patterns appear in different regions ——property 2
- Subsampling the pixels will not change the object ——property 3
兩個架構 convolution架構:針對property 1和property 2
max pooling架構:針對property 3
一個理念 針對不同的application要設計符合它特性的network structure,而不是生硬套用,這就是CNN架構的設計理念:
應用之道,存乎一心